What if a computer could generate a realistic image of your face using only your genetic information?
That's precisely the technology researchers at Human Longevity, a San-Diego based company with the world's largest genomic database, claim to have developed. The team, led by genome-sequencing pioneer Craig Venter, reported their findings in a controversial paper published in the journal Proceedings of the National Academy of Sciences.
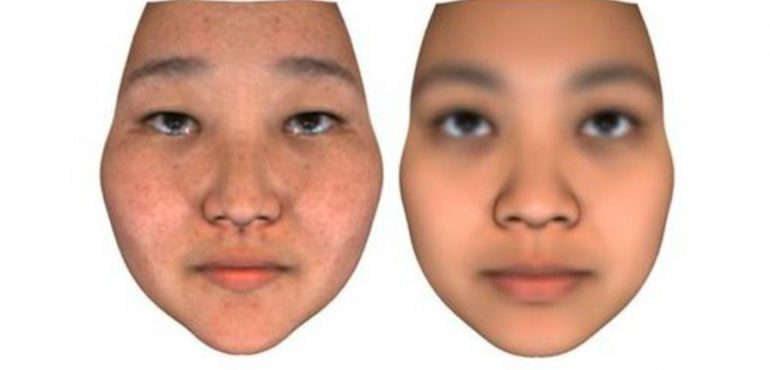
To train the A.I. to generate facial images, the team first sequenced the genomes of 1,061 people of various ages and ethnicity. They also took high-definition 3D photos of each participant. Finally, they fed the photos and genetic information to an algorithm that taught itself how small differences in DNA relate to facial features, like cheekbone height or protrusion of the brow. The algorithm was then given genomes it hadn't seen before, and it used them to generate images of the individual's face that could be reliably matched to real photos.
Well... sort of.
The team successfully matched eight out of ten images to the real photos. However, this rate fell to just five out of ten when researchers analyzed participants of only one race, considering facial features differ slightly by race. Judge for yourself how well the algorithm did:



The potential applications of this technology are especially intriguing for fields like forensic science — what if investigators were able to use genetic information left at a crime scene to “see” the perpetrator?
Interesting as the applications may be, Human Longevity is more concerned with the implications its findings has on privacy in genomics research, namely that technologies like this could be used to match people's thought-to-be anonymous genetic information to their online photos.
“A core belief from the HLI researchers is that there is now no such thing as true deidentification and full privacy in publicly accessible databases,” HLI said in a statement.
Overblown claims?
Privacy concerns seem to be widely shared in the community. But some scientists say that the paper is misleading. One reason is that the Human Longevity researchers already knew the age, sex and race of the participants — demographic information that could have been used to achieve the same matching rate without using the computer-generated photos at all.
“I don't think this paper raises those risks, because they haven’t demonstrated any ability to individuate this person from DNA,” said Mark Shriver, an anthropologist at Pennsylvania State University in University Park, in an interview with Nature.
Jason Piper, a former employee of Human Longevity, took issue with what he considered a lack of accuracy in the images, writing on Twitter that:
“everyone looks close to the average of their race, everyone looks like their prediction.”
But perhaps the most exhaustive criticism came from computational biologist Yaniv Erlich, who published a paper entitled Major flaws in "Identification of individuals by trait prediction using whole-genome sequencing data, part of which reads:
“The results of the authors are unremarkable. I achieved a similar re-identification accuracy with the Venter cohort in 10 minutes of work without fancy face morphology...”
Just days later, the team behind the original paper issued a rebuttal, titled simply No major flaws in "Identification of individuals by trait prediction using whole-genome sequencing data.
(It may seem mundane to those outside the field, but it's a pretty vicious beef in the scientific community at the moment, as seen by the "shots fired!"and "I'm gonna grab my popcorn..." comments under both papers.)
Access to genomics data
Underlying this whole debate is a question of access. Genomic data is used across various fields of study, but perhaps most importantly in research that seeks to combat diseases. In an interview with Nature, Piper said that Human Longevity has a vested interest in restricting access to DNA databases because it's a for-profit company that's trying to build the largest genome database in the world.
“I think genetic privacy is very important, but the approach being taken is the wrong one,” Piper said. “In order to get more information out of the genome, people have to share.”
Rather than privatizing and restricting access to genomic data, Piper said that a better solution would be to make data public while using techniques that still allow individuals to remain anonymous.
Source: BIGTHINK, Full Article